


AI: The King is Dead (almost), Long Live the King. RTZ #336
...OpenAI GPT-5 soon goes exponential over GPT-4 on AI Scaling Laws


The last few months this year has seen a spate of new LLM AI models from companies around the world announcing their latest and greatest new versions with benchmarks that equal and sometimes exceed the current LLM AI leader: OpenAI’s GPT-4 Turbo. That model of course is the foundation for the company’s class-leading ChatGPT, as well as all the AI Copilot services on which Microsoft has based its near-term fortunes. So this early in 2024, we have a close horse race, as they run around seemingly never-ending laps in versions, benchmarks and performance claims.
In fact, with Anthropic’s recent release of Claude 3, Ars Technica announced: “‘The King is Dead’—Claude 3 surpasses GPT-4 on Chatbot Arena for the first time”:
“On Tuesday, Anthropic's Claude 3 Opus large language model (LLM) surpassed OpenAI's GPT-4 (which powers ChatGPT) for the first time on Chatbot Arena, a popular crowdsourced leaderboard used by AI researchers to gauge the relative capabilities of AI language models. "The king is dead," tweeted software developer Nick Dobos in a post comparing GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. "RIP GPT-4."

The spate of new models include everyone from Google’s latest Gemini offerings to Anthropic’s latest Claude, to Meta’s latest open source Llama 3 and Meta AI service, to Databricks’ open source DBRX, to Mistral’s latest Mixtral, to Vicuna’s latest 13 billion parameter model today. Also today saw OpenAI partner Microsoft release Phi-3, it’s next version of their ‘Small Language Model’, SLM, that fare well against OpenAI’s GPT 3.5, which is still a work horse LLM AI for many users and businesses.
The point is that at this early stage of the AI Tech Wave, there is a feeling that competitors far and wide, big and small, have closed the gap with the champ.
And they have for now.
But the AI industry is uniquely different than prior tech waves in that it’s driven by relatively insane and exponential AI Scaling Laws. It’s something I’ve discussed before, and is the foundation of the what makes the 1,000+ strong OpenAI team under founder/CEO Sam Altman tick.
They’re deep believers in scaling LLM AI models, with sufficient investment in bigger models trained on bigger pools of curated and fine-tuned Data, can deliver exponential leaps every couple of years that leave the tech history’s venerable Moore’s Law in the dust. Especially on the future versions of training and inference loops.
With ‘Accelerated Computing’ provided by ever faster AI GPUs, AI data center infrastructure, new sources of Data, and more Power, one can expect to see 10x plus returns in both the AI hardware and software every couple of years or less for the foreseeable future. And with great AI scalability, comes incredibly higher performance for end users.
In fact so much better performance that the teams at OpenAI think it’ll make today’s GPT-4 and comparable models look utterly unimpressive in hindsight. In fact Sam Altman is on record saying this year that GPT-4 ‘kind of sucks’, RELATIVE to what’s coming.

While GPT-5 is not officially announced or released, some form of it is expected later this year. A possibility is it being announced at Microsoft’s Developer Build Conference in late May, but that is a speculation at best for now.
And if earlier rumors of OpenAI and Apple potentially doing a deal around it’s LLM AI models, a possible alternative time frame could be Apple’s WWDC Developer Conference in June this year. Or it could be later this year when OpenAI is good and ready.
Furthermore, we know that OpenAI is trying to figure out additional ways to enhance AI services with Search and other ‘Agentic AI workflow’ services. All that would also work better with GPT-5 in some form over GPT-4.
Although Sam Altman has not cited any metrics around how much GPT-5 can scale over GPT-4, OpenAI COO Brad Lightcap did mention a number as high as 100x in a recent podcast interview with 20VC in London. The number was cited in general terms rather than specific to any upcoming OpenAI product, but it was directionally useful in any case.

A 100x improvement over current models would be industry-jarring indeed. It would be more pedal to the metal for the industry, especially in the need for more ‘metal’ in terms of AI GPU chips, data centers and more power infrastructure. And it’d give more credence to the tens if not hundreds of billions being bandied around by tech company heads as their capex investment goals for the foreseeable future.
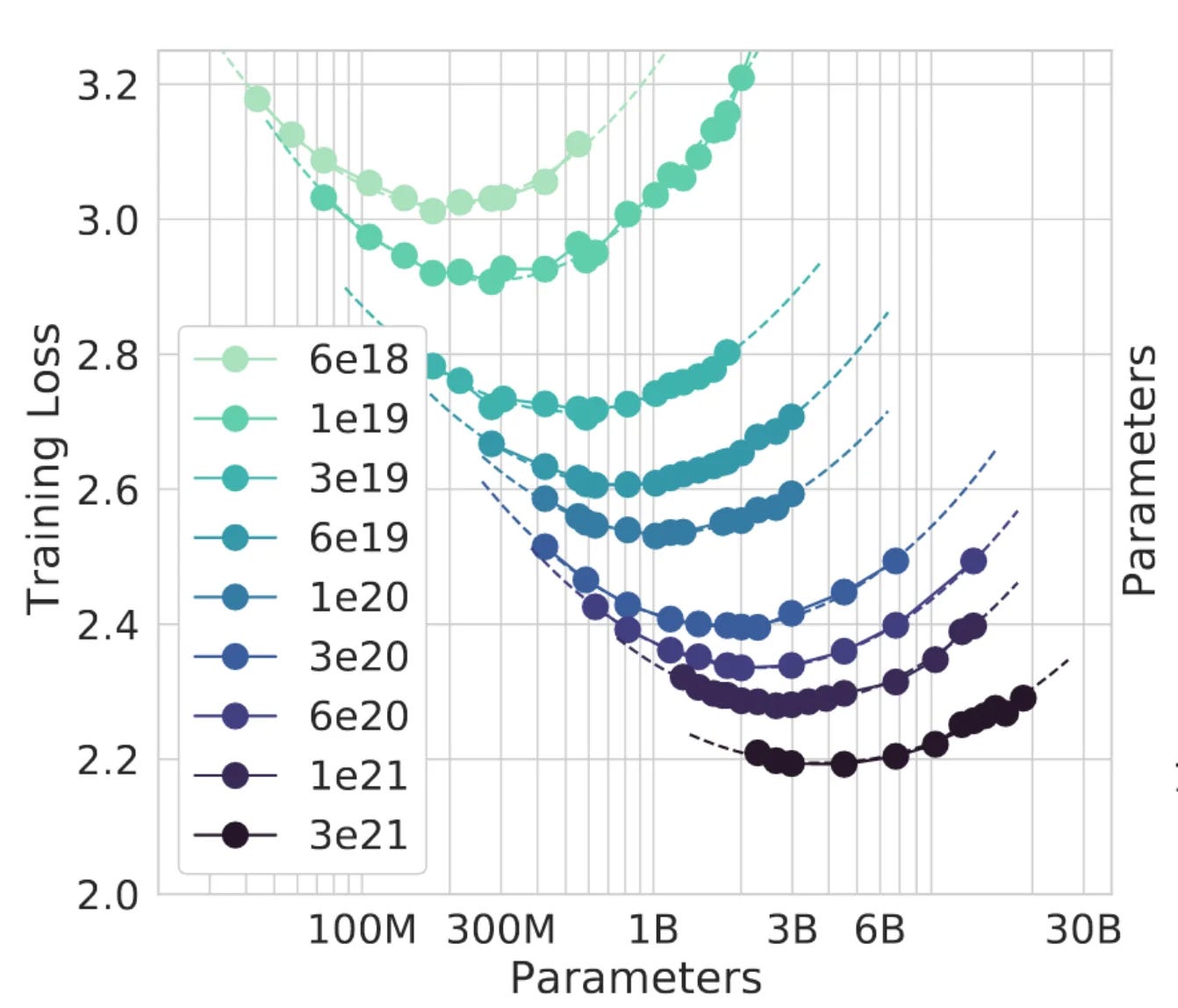
If the industry can maintain an execution path along AI Scaling laws, even for the next 3-5 years, this AI Tech Wave is going to be a very different thing than prior cycles. Ever higher AI Compute, with ever lower Costs at Scale.
It’s definitely the game plan being focused on by industry leaders like OpenAI. And all the others in the race will have to ramp up for the next exponential lap in the race.
Long live the King indeed. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)