


AI: Nvidia's Accelerating AI Strategy. RTZ #305
...Computing with a lot more than just 'GPUs'

The Bigger Picture, Sunday March 24, 2024

Earlier this week, I discussed at length, Nvidia’s rocking Developer Conference at their GPU GTC 2024 Conference this week, complete with founder/CEO rock star of the moment Jensen Huang with 11,000 plus in approving attendance. There were so many notable items on Nvidia’s product roadmap in the two plus hour keynote, and combined with the truly long game being played by Jensen in AI for over a decade, I thought it’d be helpful to take a look at The Bigger Picture of Nvidia in the context of the AI Tech Wave. And explain the deeper technical bits in a more mainstream context. Let me unpack.

If OpenAI’s AI software innovations with GPT and ChatGPT kicked off the current iteration of the AI revolution, it was Nvidia’s AI GPU (Graphical Processor Unit) hardware and software, that made them really REAL at scale. As I’ve long said, ‘AI’ without the GPUs to do the math compute would just be two non-adjacent letters in the library. And Google’s seminal ‘Attention is all you need’ AI paper that gave the world the ‘T’ for Transformers in OpenAI’s GPT, would just be an interesting mathematical computing exercise. This is a world where a ‘billion quadrillion’ math computations in micro-fractions of a second, are currently just the starting point in 2024. Training, Inference, and all.
Jensen Huang has been focused on AI eating Software as Software Eats the World for over a decade now. As he highlighted on stage at the keynote, Nvidia’s key AI ‘Eureka’ moment was when Alexnet, a key AI project that Nvidia backed in 2013, managed to convert millions of images and figure out what makes a cat a ‘Cat’. And spit out the text.

And as Jensen pithily summarized in the keynote, the last decade has been about Nvidia building out the AI GPU hardware and software to enable so many companies building on the Nvidia platform to now convert text on Cats into amazing images and videos on Cats and everything imagined by humans. And beyond.
The overall theme Jensen Huang has been using for a while now is that Nvidia has been about enabling new markets with ‘Accelerated Computing’, for its three plus decades of ‘overnight success’. This is useful to keep in mind, especially as AI computing, driven by Nvidia hardware and software in particular, is poised to deliver 10x and beyond AI compute performance for the next few years. Far beyond the 2x in two plus years long promised and delivered in the tech industry by ‘Moore’s Law’ for decades now.
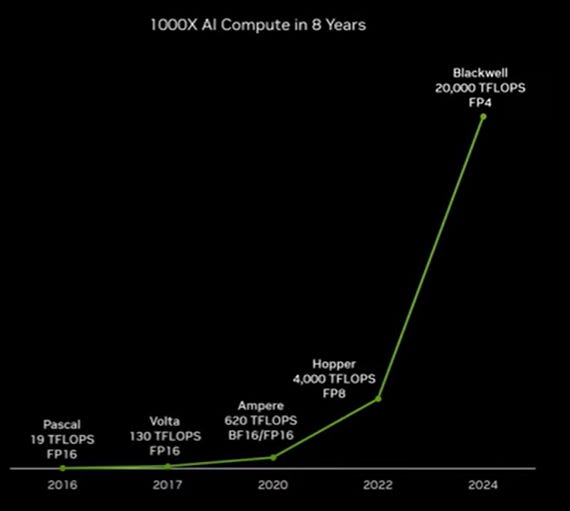
That is the bigger picture context on what drives Nvidia and its founder/CEO today. The rest are details on the immediate next steps of how the AI Tech Wave gets build from its current very early years.
Let’s go through some of that near-term product roadmap. In relatively non-technical language.
Given that AI itself is truly about exponentially growing MASSIVE MATH, it’s spot on that Nvidia’s GPU/CPU chip families are named after famous mathematicians/scientists. Nvidia's current 'king of the hill' AI GPU chip is the H100, which is the Hopper line, named after Grace Hopper. Goes at prices of $30,000 and up. Meta alone is deploying over 350,000 H100s and 600,000 of 'equivalent compute'. So budgets of billions of course.
At GTC 2024, Jensen Huang introduced the Blackwell chip line named after David Blackwell.

Grace Brewster Hopper (née Murray; December 9, 1906 – January 1, 1992) was an American computer scientist, mathematician, and United States Navy rear admiral.
David Harold Blackwell (April 24, 1919 – July 8, 2010) was an American statistician and mathematician who made significant contributions to game theory, probability theory, information theory, and statistics.
Here is a brief outline of the key announcements at GTC 2024 and their high-level implications:

HARDWARE:
Blackwell GPUs (B100, B200 and other derivations)
4x faster on LLM Training vs H100 GPUs, that currently sell for $30,000 plus per chip.
30x Faster on LLM Inference (answering user and API queries against the underlying trained LLM models of choice) vs H100 GPUs.
Availability, Q3 2024 onwards.
Pricing expected to be modest premiums to H100s in large volumes.
Note that Jensen said Blackwell was likely the company’s most important set of products to date.
Jensen’s $10 billion figure for the R&D behind Blackwell likely conservative when considering the additional investments/capex in Nvidia networking and software infrastructure.
The chips are not sold individually, but as ‘Superchip’ boards, racks, and AI datacenter services under names like DGX, Omniverse and now NIMs, expained below
The Superchips are clustered into Racks with other supporting CPUs (like the Grace and soon Blackwell CPUs, and networking chips and boards that make up Nvidia’s NV Link and NV Switch products.
Example of a ‘Superchip’ is the GB200, which combines two Blackwell GPUs with one Grace CPU.

This enables very high performance AI training and inference.
Example of NV Link and Switch products are what goes into a product rank like the NVL72:

NVL72 Rack includes 72 Blackwell GPUs and 36 Grace CPUs.
Can train extremely large LLM AI models to come as large as 27 million parameters.
As comparison, GPT 3 was less than 200 billion parameters, and GPT 4 is around 1.8 billion parameters.
Meta’s Llama 2 and 3 models come in sizes of 7, 70 billion parameters and higher.
This is the Fifth Generation of the NVLink product.

It enables faster connectivity between the GPUs and CPUs.
And allows scaling across multiple racks.
This is more important with next generation LLM AI models with larger parameters and token utilization.
Tokens are the basic unit GPUs do their math computations for LLM AI training and inference. The larger the ‘token window’, the more amounts of Data the user can inject into their prompt inquiries. Token windows are rapidly going from thousands at a time to now millions and soon tens of millions. Very important going forward especially for multimodal LLM AI applicsations at scale.
NVLink substantially offloads more of the Compute burden to the more powerful Blackwell GPUs vs the Hopper line of GPUs.
Much more important for the next generation of LLM AIs like Gemini Ultra, OpenAI GPT 4.5, and GPT-5 when it comes out.
Allows near-instantaneous training and inference calculations in the ‘billion quadrillions’ as Jensen highlighted in keynote.
All of the above GPU chips, boards and NVLink/NVSwitch products make the Commercial offerings possible that Nvidia then sells wholesale to the AI Cloud datacenter providers like Amazon AWS, Microsoft Azure, Google Cloud, Oracle Cloud, CoreWeave and others.
This cements their position further as both the AI cloud/data center companies AND their customers build their products and services above this Nvidia hardware layer. So Nvidia's market share is bolstered further up the AI Tech Value stack potentially for years.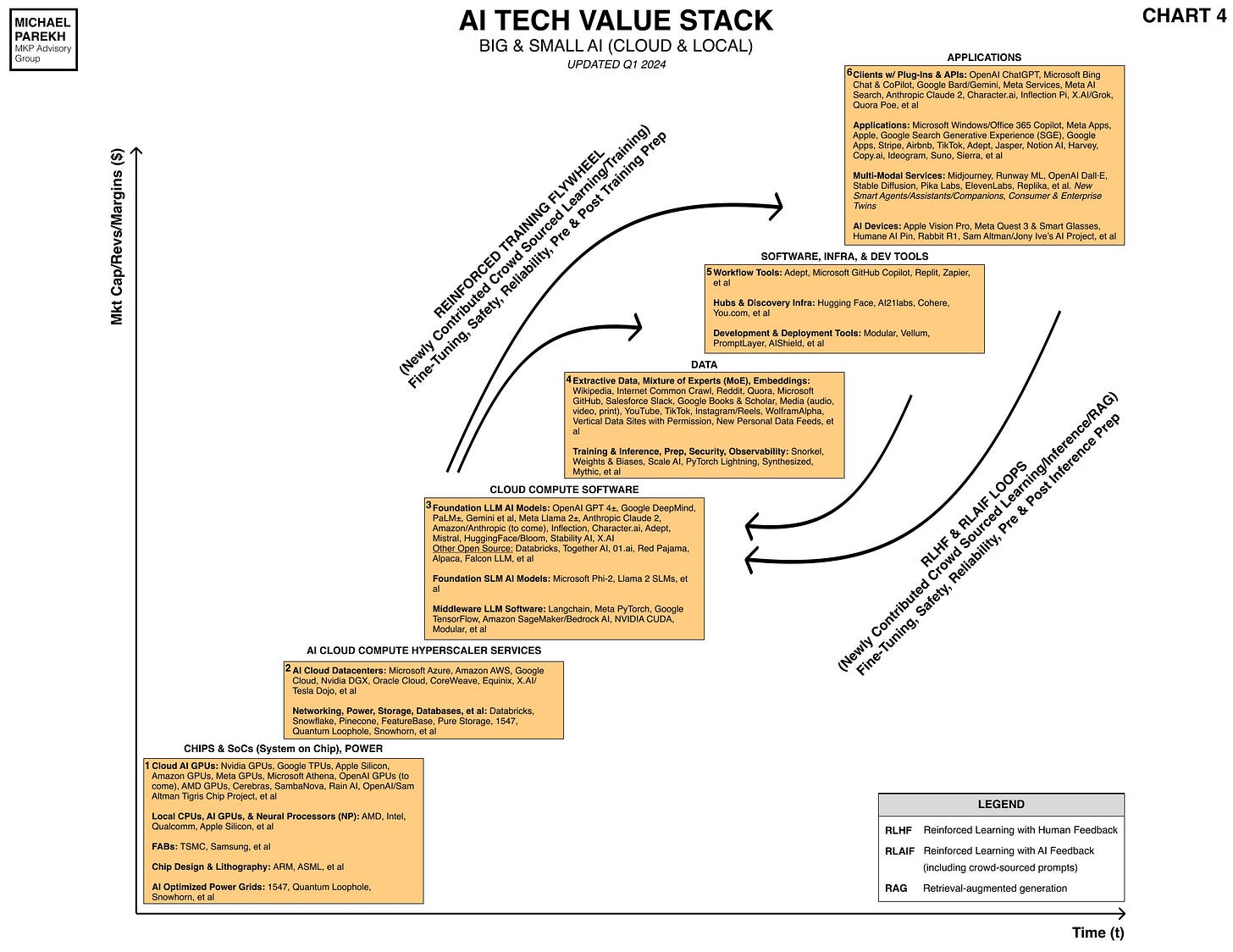
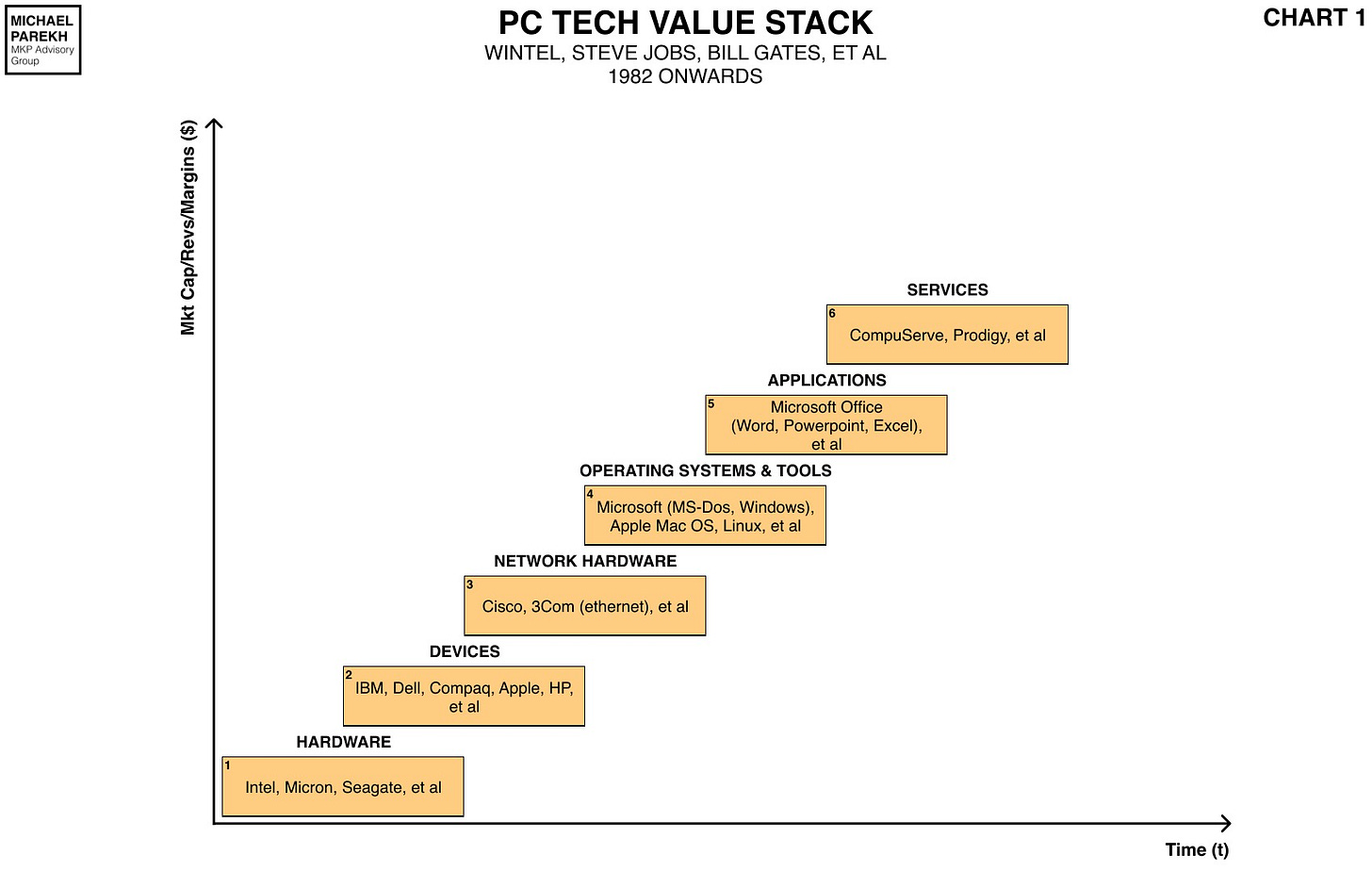
Not unlike how Microsoft built its business in the PC and Internet waves on software infrastructure tools, operating systems, and applications.
These Nvidia racks and clusters are what goes into the Nvidia AI data center products and services marketed as ‘DGX’ Superpods.
The other major Commercial product they announced at GTC was NIM, which stands for Nvidia Inference Microservices. This is Nvidia’s visual brand for NIM:

These are pre-built software and model packages that allow enterprise customers to mix and match their own choice of LLM AI models (open or closed), with their own data.

These can then allow them to build out their own AI applications and services customized for their own vertical industries like healthcare, manufacturing, etc. Nvidia provides lots of additional software tools and infrastructure, customized for those industries.
Nvidia NEMO represents additional Nvidia software infrastructure that allows enterprises to build out industrial-scale AI services for their customers.
This is all part of the Nvidia ‘AI Foundry’ and ‘AI Factory’ services he was talking about. They're customized to vertical industries and major customers.
Nvidia Omniverse is Nvidia’s offering for Enterprise customers to build out ‘digital twins’ of their facilities and factories, with capabilities for global 3D collaboration.
Key customers highlighted as examples were in the automotive, shipping and other industries.
Lots of Omniverse service updates announced.
COMPETITION:
While their key big tech customers are ramping up their own AI GPUs and infrastructure, the full portfolio of Nvidia products above (and many others not highlighted here), provide a formidable lead for Nvidia on its 70% plus market share in GPUs and AI data center infrastructure.
The other competition of course from their best customers include Google TPUs, Microsoft Maia, Meta MTIA, Amazon AWS’s Trainium and other chips.
And of course AMD’s MI300, Intel Gaudi, and chips from newcomers like Cerebras, Groq and many others.
But the overall Portfolio of hardware, networking, software infrastructure like CUDA and other tools, bundled into scaled AI services and now ‘NIMs' microservices offer very different options for both types of customers: Cloud, and end Enterprises across industries. And makes it difficult to root out Nvidia GPUs and hardware for competing options.



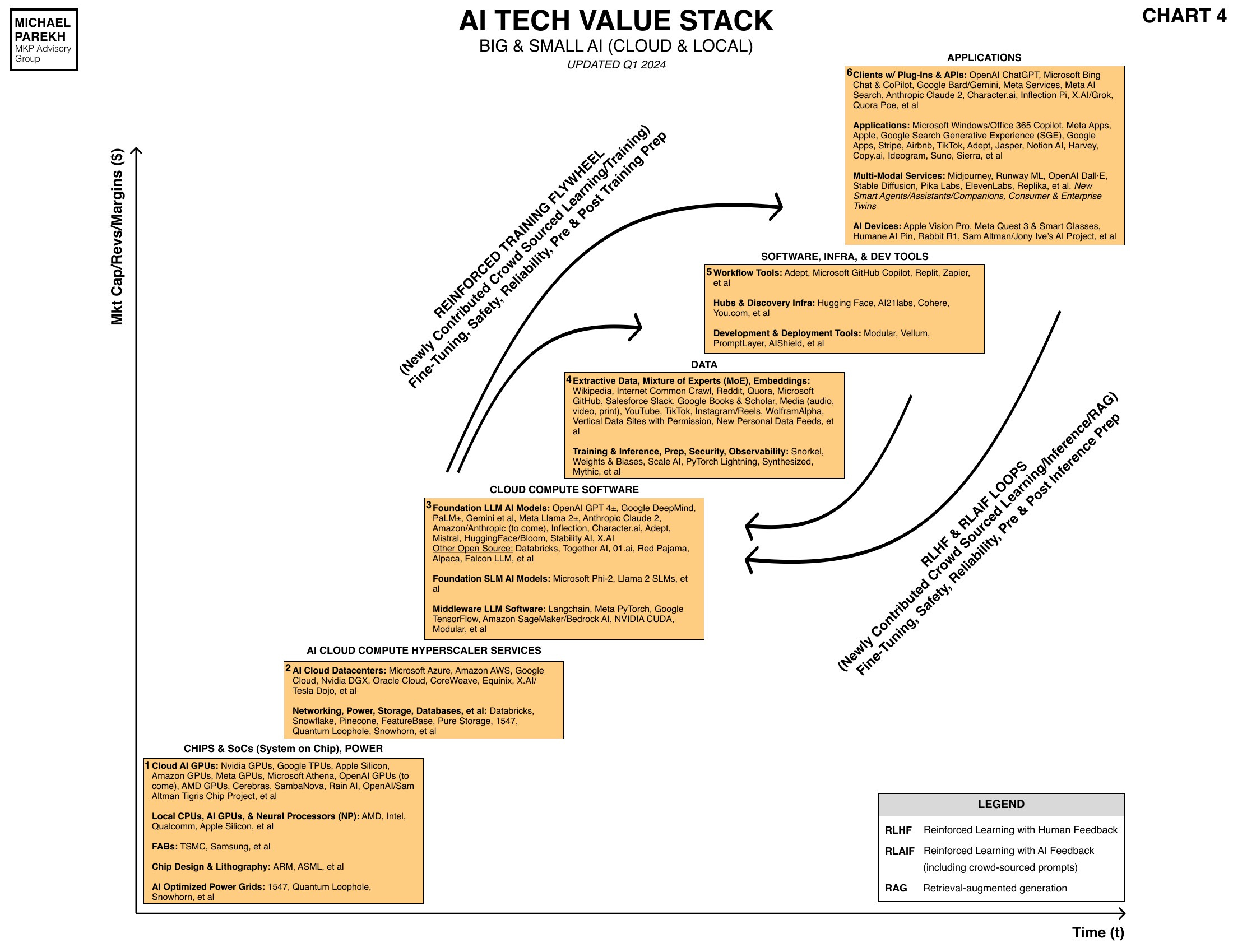


Will stop this Nvidia product road map on AI GPU hardware and software here.
 - YouTube")
Will leave Jensen’s product plans in the area os AI Foundation Robots and Robotics for a separate post. At a high level it’s Nvidia’s ‘Groot Foundation Model’ for Humanoid Robots and Isaac Robotics Platform, that Jensen highlighted in the company of multiple robots on the key note stage.
Hope this provides useful context on Nvidia’s opportunities, strategies and position in ‘accelerated computing’ world of the AI Tech Wave. And a bit of the Bigger Picture. Stay tuned.