

Long-time readers here are familiar with my focus on the never-ending quest for Data for training and inference in the next gen LLM AI models in the AI Tech Wave race. It’s the next key AI input after AI GPU chips and Power to run the massive OpenAI/Microsoft ‘Stargate’ size AI data centers to come.
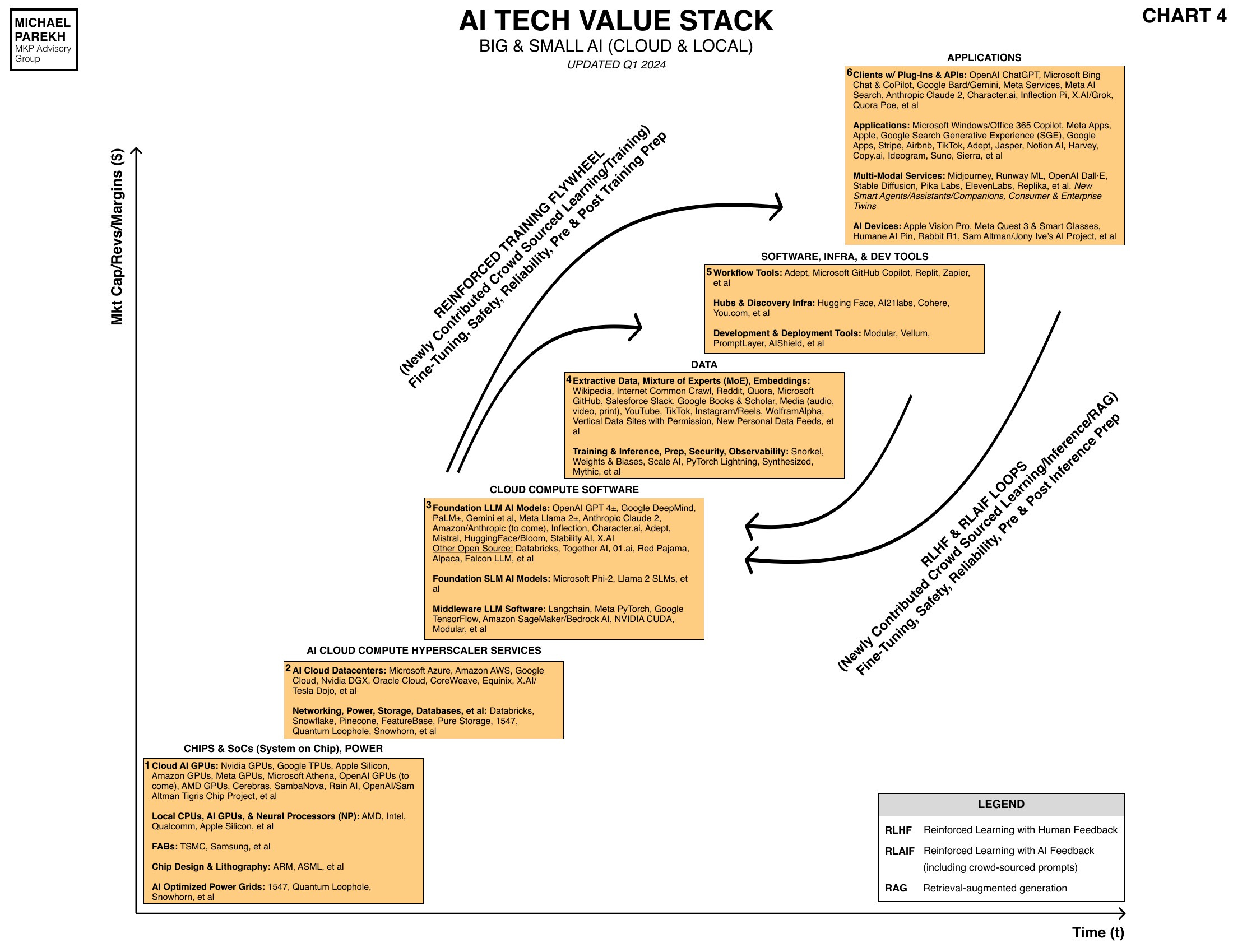
As I explained last fall, Box 4 above titled ‘Data’, also called ‘Extractive Data’ in the LLM AI context, is the key differentiating part of the AI Tech Stack, relative to the PC, Internet and other tech waves and cycles. Feeding ever more powerful GPUs and Models, as recently highlighted in roadmaps by Nvidia, OpenAI and others in AI hardware and software infrastructure. It’s a never ending stream of probabilistic calculations built ‘On the Shoulders of Giants’, (OTSOG), revised for the digital age.

These AI models are growing 5x plus a year in size and capability every year at least. And their need for data is growing exponentially as well. The WSJ’s timely “For Data-Guzzling AI Companies, the Internet is too Small”. With the alarming sub-headline
“Firms such as OpenAI and Anthropic are working to find enough information to train next-generation artificial-intelligence models.”
It goes on to explain:
“Companies racing to develop more powerful artificial intelligence are rapidly nearing a new problem: The internet might be too small for their plans.”
“Ever more powerful systems developed by OpenAI, Google and others require larger oceans of information to learn from. That demand is straining the available pool of quality public data online at the same time that some data owners are blocking access to AI companies.”
“Some executives and researchers say the industry’s need for high-quality text data could outstrip supply within two years, potentially slowing AI’s development.”

“AI companies are hunting for untapped information sources, and rethinking how they train these systems. OpenAI, the maker of ChatGPT, has discussed training its next model, GPT-5, on transcriptions of public YouTube videos, people familiar with the matter said.”
“Companies also are experimenting with using AI-generated, or synthetic, data as training material—an approach many researchers say could actually cause crippling malfunctions.”
“These efforts are often secret, because executives think solutions could be a competitive advantage.”
And how we got to this point:
“The data shortage “is a frontier research problem,” said Ari Morcos, an AI researcher who worked at Meta Platforms and Google’s DeepMind unit before founding DatologyAI last year. His company, whose backers include a number of AI pioneers, builds tools to improve data selection, which could help companies train AI models for cheaper. “There is no established way of doing this.”
“Data is among several essential AI resources in short supply. The chips needed to run what are called large-language models behind ChatGPT, Google’s Gemini and other AI bots also are scarce. And industry leaders worry about a dearth of data centers and the electricity needed to power them.”
“AI language models are built using text vacuumed up from the internet, including scientific research, news articles and Wikipedia entries. That material is broken into tokens—words and parts of words that the models use to learn how to formulate humanlike expressions.”
“Generally, AI models become more capable the more data they train on. OpenAI bet big on this approach, helping it become the most prominent AI company in the world.”

It goes onto explain some of the numbers at scale:
“OpenAI doesn’t disclose details of the training material for its current most-advanced language model, called GPT-4, which has set the standard for advanced generative AI systems.
“But Pablo Villalobos, who studies artificial intelligence for research institute Epoch, estimated that GPT-4 was trained on as many as 12 trillion tokens. Based on a computer-science principle called the Chinchilla scaling laws, an AI system like GPT-5 would need 60 trillion to 100 trillion tokens of data if researchers continued to follow the current growth trajectory, Villalobos and other researchers have estimated.”
“Harnessing all the high-quality language and image data available could still leave a shortfall of 10 trillion to 20 trillion tokens or more, Villalobos said. And it isn’t clear how to bridge that gap.”
“Two years ago, Villalobos and his colleagues wrote that there was a 50% chance that the demand for high-quality data would outstrip supply by mid-2024 and a 90% chance that it would happen by 2026. They have since become a bit more optimistic, and plan to update their estimate to 2028.”
I’ve been more optimistic that we’ve barely scratched the tip of the potential AI Data iceberg, as I outlined last June.

The WSJ echoes the same point at the end, citing both new data sources and the promise if ‘synthetic data’, despite current issues of innovating beyond ‘model collapse’ issues:
“Companies also are experimenting with making their own data.
“Feeding a model text that is itself generated by AI is considered the computer-science version of inbreeding. Such a model tends to produce nonsense, which some researchers call “model collapse.”
“Researchers at OpenAI and Anthropic are trying to avoid these problems by creating so-called synthetic data of higher quality.”
“In a recent interview, Anthropic’s chief scientist, Jared Kaplan, said some types of synthetic data can be helpful. Anthropic said it used “data we generate internally” to inform its latest versions of its Claude models. OpenAI also is exploring synthetic data generation, the spokeswoman said.”
“Many who study the data issue are ultimately sanguine that solutions will emerge. Villalobos compares it to “peak oil,” the fear that oil production could top out and start an economically painful collapse. That concern has proven inaccurate thanks to new technology, such as fracking in the early 2000s. “

Fears of ‘Peak Oil’ had in fact surfaced in the early days of the oil industry, after the first major strikes in Pennsylvania, Texas and other places. It took a century plus of technology innovation and global exploration of course to side-step that issue through the 20th century.
The current concerns over ‘Peak Data’ may be as premature as well. Indeed, recent innovations like OpenAI’s text to video AI model Sora may not be possible without innovative work around training and inference on multimodal audio/video/coding content.

We’ve barely started on the quest for AI scale and applications. The data sources to come will likely be surprisingly abundant with further AI tech innovation to come. We just have to 'Wait for it’ all. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)
What if the solution is efficiency? If these models hit limits associated with power, chip count, and available data it would seem the push should be towards building more efficient models. Easier said then done I guess.