
AI: Small AI gets Bigger
...open source small LLM AI make moves

What I’ve been calling ‘Small AI’ , in this AI Tech Wave, had a couple of notable developments this week. They advanced their capabilities against peers and even much larger Foundation LLM AI models (what I’ve been calling ‘Big AI’), on some measures.
‘Small Language Models (SLMs)’ on local devices, complementing the Foundation ‘Large Language Models (LLMs)’. The latter of course have captured most of the attention and investment dollars in the first full year post OpenAI’s ChatGPT. Let me re-set the context.
Here’s the AI Tech Wave chart again for background for some of the discussion below.
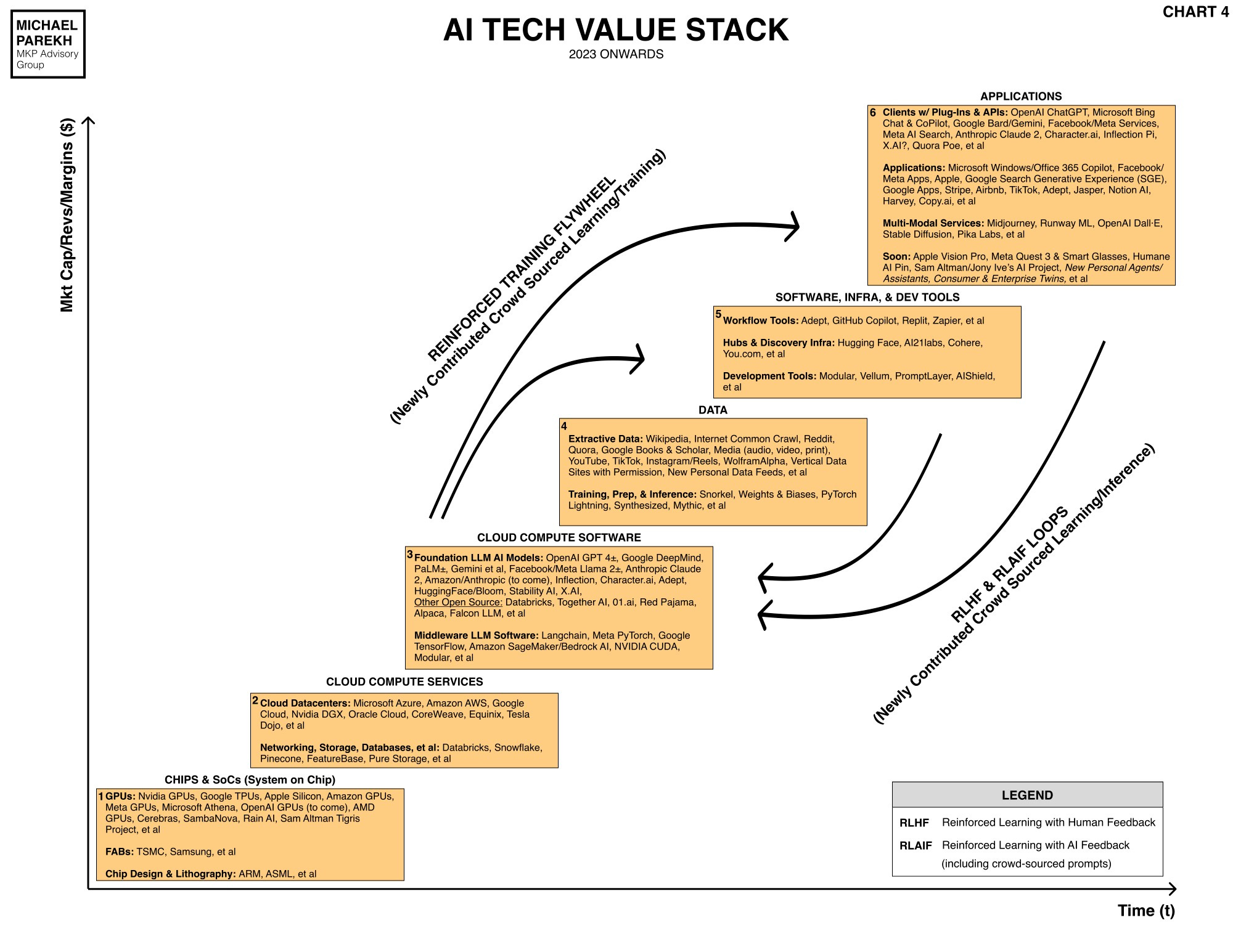
Back in September, in a post titled “From Big AI to Small AI”, I highlighted:
“Big AI is where the industry’s attention and dollars are curretly riveted on: Foundation LLM AI models that are getting exponentially powerful running on ever more powerful GPUs, in ever bigger Compute and power intensive data centers.”
“Think AI possibly a thousand times more powerful than today’s OpenAI GPT4, Google Palm2/Bard (and upcoming Gemini), and Anthropic’s Claude 2 in three years or less. That sure beats Moore’s Law by a mile and then some. As discussed earlier, over two hundred billion dollars are being invested worldwide to get ready for these ‘Big Daddy’ Foundation LLM AI models.”
“Ok, so where does ‘Small AI’ fit? These are far humbler and prosaic, but again ever more powerful LLM AI models increasingly being run on billions of devices already in the hands of over 4 billion users of smartphones and other computers ‘locally’. Also known as ‘the Edge’ as I’ve referred to it here and here. They're starting small today on photo and other apps on your phone, and will spread to almost every app and services on billions of local devices, tapping into near infinite local and cloud data sources. “
The Information notes today in “The Rise of ‘Small Language Models’ and Reinforcement Learning”:
“This week, several companies staked out new ground in the latest forefront of AI research: trying to prove that their models can do more with less. On Monday, the French AI startup Mistral—fresh off its $415 million funding round—published a new model called Mixtral 8x7B. The model, which is open-source, quickly racked up plaudits from AI researchers for its ability to match the quality of GPT-3.5 on some benchmarks despite its relatively puny size. Mixtral is small enough to run on a single computer (albeit one with a fairly hefty 100 gigabytes of RAM).”
“Mixtral 8x7B gets its name because it combines various smaller models that are trained to handle certain tasks, thereby running more efficiently. (It’s an approach called a ‘sparse mixture of experts’ model). Such models aren’t easy to pull off—OpenAI previously had to scrap development of a mixture of experts model earlier this year after it couldn’t get it to work, The Information previously reported.”
“Then, on Tuesday, Microsoft researchers published the latest version of their home-grown model called Phi-2. That model was tiny enough to run on a mobile phone, with just 2.7 billion parameters compared to Mixtral’s 7 billion (remember, OpenAI’s GPT-4 is believed to have around a trillion parameters across a number of expert models). It was trained on a carefully-selected dataset that is a high enough quality to ensure the model generates accurate results even with the limited computing power available on a phone.”
“Microsoft touted it as a “small language model,” a relatively new term for a category that Microsoft’s research division is leaning into heavily. It’s not yet clear exactly how Microsoft or other software makers might put small models to use, but the most obvious benefits would be driving down the cost of running AI applications at scale and dramatically broadening the usage of generative AI technology. That’s a big deal.”
It’s a big deal indeed. And other big tech companies (aka ‘Magnificent 7’) have yet to announce their moves in ‘Small AI’. I’m of course referring to Apple, along with a range of other technology companies that have yet to scale their AI moves.

In “Going Small to Go BIg” this November, I emphasized”:
“As I’ve highlighted before, Apple has led on this trend with over two billion devices in user hands:
“Apple has been including a neural engine as part of its homegrown processors since it introduced the A11 processor in the iPhone 10 in 2017.”
“This past Monday night, Apple unveiled its latest MacBooks during a rare prime-time event, a sign of its renewed focus on its own PC division. The latest MacBook Pros, along with an upgraded iMac, will all use a version of the company’s new M3 processors. Apple said the high-end version of the chip, called the M3 Max, will be capable of running complex AI workloads.”
“Chip makers AMD, Intel, Qualcomm, Micron, and others are all accelerating their efforts with AI chips particularly optimized for local ‘reinforced learning loops’ for AI inference at ‘the Edge’, which are going to be the primary driver of how users augment themselves with AI going forward.”
Key point here is that AI innovation is just beginning. It’s coming fast and furious. It will be open and closed AI, Narrow and Wide AI, and also Big and Small AI.
All of these developments and more will give us far more augmented and native AI applications and services soon. Far beyond OpenAI’s ChatGPT, which kicked it all off just over a year ago. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)