
AI: Nvidia the new Nike
…marathon barely started

(Update 9/11/23: There is an updated piece by the Information on Nvidia’s data center strategy with the leading data center hosting companies worth reading. Highlights the complex calculus of each of the parties given the white hot global demand by businesses for Nvidia GPUs and software, to deploy AI services based on their own data-driven models, and the acute shortage and allocation of Nvidia GPUs at least through 2024. It also touches on Amazon AWS’s delicate balance of offering Nvidia GPU based servers to its business customers without yet offering Nvidia’s DGX datacenter services).

Given the natural human need to understand infinite games in finite terms (aka “Are we there yet?”), we are constantly looking for winners and losers every step of the way. Yesterday, I talked about the race having just begun for the trillions in GDP growth ahead over the next decade, for businesses increasingly deploying AI driven cloud software and hardware ‘Compute’ infrastructure. This AI Tech wave has just seen the starting gun go off.
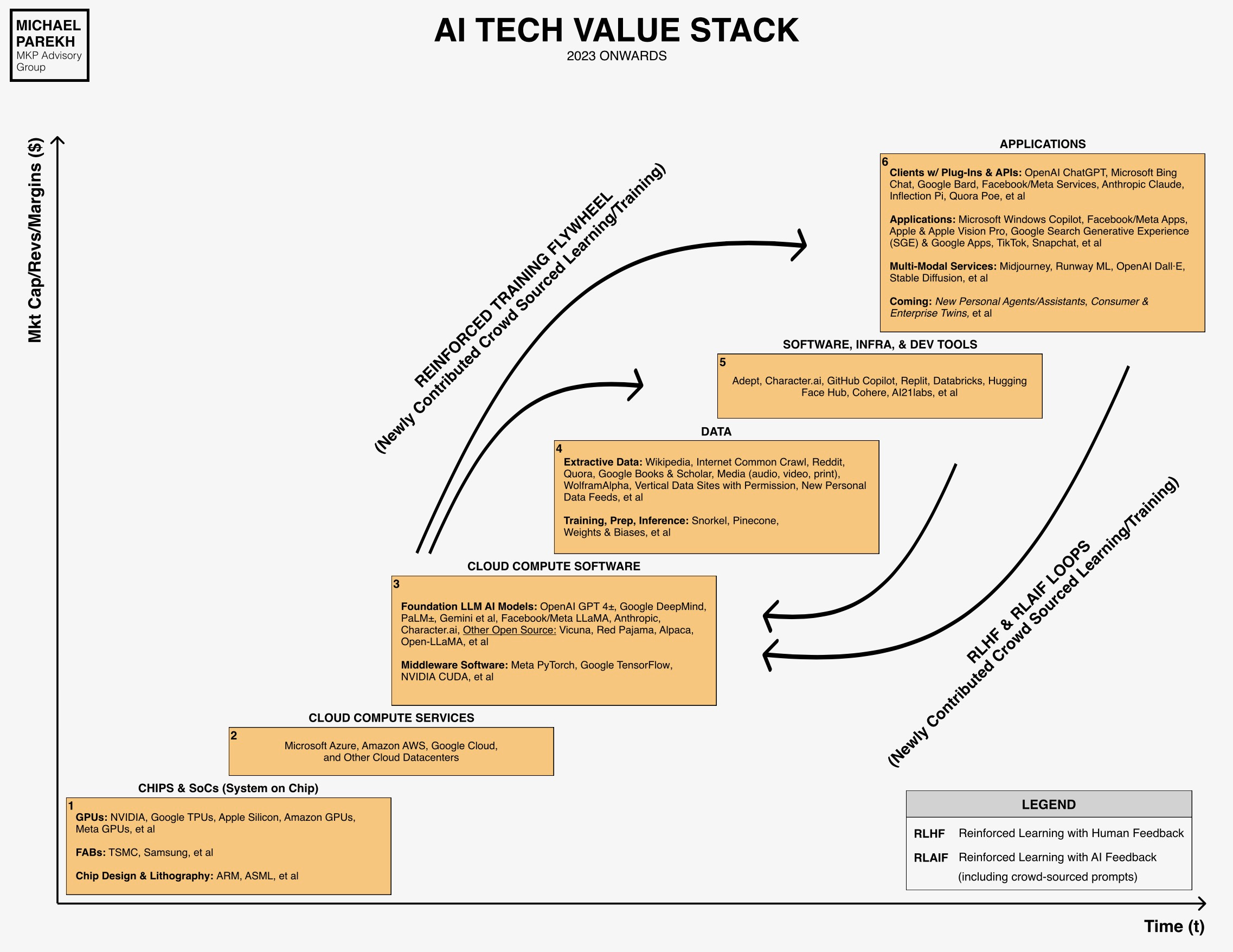
The marathon barely began nine months ago with OpenAI’s ‘ChatGPT’ moment, although the industry has been ‘carb-loading’ and training in mini-marathons since at least 2017, when eight Google researchers published their now famous AI “Attention is All you need” Transformer paper, that really kicked the preparations for this race off. And launching a bunch of new AI ‘Unicorns. Almost every day sees new ones, like Israeli firm AI21 Labs this week (Box no. 5 above), innovating around LLM AI models and AI software infrastructure, as reported by Stephanie Palazzolo of the Information.
OpenAI and Microsoft have announced their Enterprise AI offerings in the last few weeks, as have competitors Google, Amazon, Meta, and Nvidia for the same ultimate prize. Although Amazon has been the global market leader in cloud services globally to businesses large and small, with over $80 billion in revenues for its Amazon AWS cloud business that provides the majority of Amazon’s overall profits, the number two player Microsoft, with less half that in revenues last year, has taken the lion’s share of global attention with its seminal $13 billion plus LLM AI partnership and 49% stake in OpenAI and it’s GPT4 and ChatGPT crown jewels.

Google, the number three in enterprise Cloud services with over $25 billion in revenues just in that business, has more than responded in recent months, and is very much in the race at this early stage, with a range of formidable advantages ranging from Compute ‘TPU’ (Tensorflow) hardware at global scale, to a cluster of next generation LLM AI software products like Gemini and more.
Amazon as I’ve highlighted in an earlier piece, is less of an underdog as has been perceived by the industry, despite its current lead in the global market share of enterprise cloud computing services. The Information has a fresh piece with more history and blow-by-blow color on Amazon AWS steps that may have contributed to this perceived underdog status. A piece worth reading for those interested in the details. But they like Google, have more than figured out what they need to do to have a good strategy for the marathon ahead.

And as I discussed yesterday, Nvidia is in an enviable pole position in GPU and related AI hardware and software infrastructure to be both king-maker and gate-keeper with a 70% plus market share, at least until 2025 as GPU chip competition ramps up. Nvidia is almost the ‘Nike’ in this race, as this NYTimes piece reminds us of how many top marathoners used their shoes in key marathons.
Nvidia’s GPU chips and their H100 chips, along with their DGX data center CUDA compute platform, are the ‘Nike’ shoes today in the cloud data center AI race led by Amazon AWS, Microsoft Azure, Google Cloud, Oracle Cloud, CoreWeave, and many others. They all wear, err, use Nvidia GPU chips and infrastructure. It’s a direct result of Nvidia founder/CEO Jensen Huang having played the really long and smart game in AI, and invested accordingly for years.

As LLM AI models get both larger and smaller, both more open and in some ways more closed, Nvidia is making sure their DGX infrastructure is well-positioned to run them all. At both ends of the spectrum, and for businesses large and small. These costs tens of millions and up to setup in scale, and can also be bought by the ‘drink’ as an AI utility, when and where capacity is available. As this deep dive by chip research shop Semianalysis notes in a piece titled “Google Gemini Eats the World”:
“Nvidia is eating [competitors’] lunch with multiple times as many GPUs in their DGX Cloud service and various in-house supercomputers. Nvidia’s DGX Cloud offers pretrained models, frameworks for data processing, vector databases and personalization, optimized inference engines, APIs, and support from NVIDIA experts to help enterprises tune models for their custom use cases. That service has also already racked up multiple larger enterprises from verticals such as SaaS, insurance, manufacturing, pharmaceuticals, productivity software, and automotive.”

Google, the only other hardware competitor with direct semiconductor fab access with Taiwan’s pivotal Taiwan Semiconductor (TSMC), for its Tensorflow TPU chips (versions 4 and 5 soon), is also making sure their ‘shoes’, or chips can also run as wide a range of LLM AI models as possible, for both their own use (Gemini, Bard, SGE, et al), and enterprise customer use. Here too, as Semianalysis notes in the same piece above (links mine):
“Google is the most Compute Rich Firm in the World. While Google does use GPUs internally as well as a significant number sold via GCP, they a have a few Ace’s up their sleeve. These include Gemini and the next iteration which has already begun training. The most important advantage they have is their unbeatably efficient infrastructure.”
“The truly staggering thing is what happens with the next iteration which has already began training based on TPUv5. This is ~5x larger than OpenAI’s GPT-4.”
“Google’s infrastructure isn’t only going to serve their internal needs. Frontier model companies such as Anthropic and some of the largest companies in the world will also access TPUv5 for training and inference of in-house models.”
“Google’s move of the TPU into the cloud business unit [Google Cloud], and a renewed sense of commercialism has them fighting decisively for some big names wins that you will see over the coming months.”
It’s one of the reasons they’re working closely with Meta and Nvidia to make sure they can offer compute at scale as and when needed. And this is one of the reasons I made the call that Google does to OpenAI this round what Microsoft did to Netscape in the Internet wave in the nineties.
It’s definitely going to be an hyper-competitive race. It’s just begun, with at least 26 miles to go, translated in our context into at least the next three years. For companies like Google, Microsoft, Meta, Amazon, OpenAI, and especially Nvidia, this has already been at least a decade long marathon.
With the new triathlon just starting. Did I mention it was at least a triathlon? And Apple is just warming up, with startups, businesses, and developers galore jostling for position in the opening throng of runners.
The gun has just gone off. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)