
AI: Figuring out AI Explainability
...while we wait for better Interpretability and Reliability


As discussed at length in previous posts, the best AI and technology minds are in an epic, accelerated global race to build out bigger and bigger Foundation LLM AI models on ever better AI GPU hardware infrastructure as the AI Tech Wave plays out. And private and public markets globally are funding it all with hundreds of billions of dollars.
But there is also a concurrent effort to figure out how we can EXPLAIN and INTERPRET the results emanating from these ‘magical’ tools. And how much can we rely on them. This is the crux of our fears and excitement over the potential opportunities.
It’s also what is increasingly being demanded by regulators everywhere, the AI ‘Holy Grail’: Explainability, Interpretability and Reliability. Indeed, the National Institute of Standards and Technology (NIST), which is the US arbiter of measurement standards, has been focused on these questions for a while now, as seen in this report on AI and machine learning a few years ago.
In simple terms, the differences between Interpretability and Explainability in LLM AI model results, be they Big or Small, Open or Closed, is the level of detail being sought. Interpretability focuses on understanding the inner workings of the models, while Explainability focuses on explaining the ‘decisions’ made by the model serving up the answers. The former requires a far greater level of detail than the latter.
Indeed, as I’ve recounted before, the immense number of statistical calculations done for every AI query is so great, that doing a detailed amount of ‘interpretability’ analysis tracing the millions and billions of ‘reinforcement learning loop’ calculations done across the large number of ‘neural layers’ in the model can require an amount of human time and attention that could run into multiple lifetimes and beyond. Thus likely unattainable with just human power.
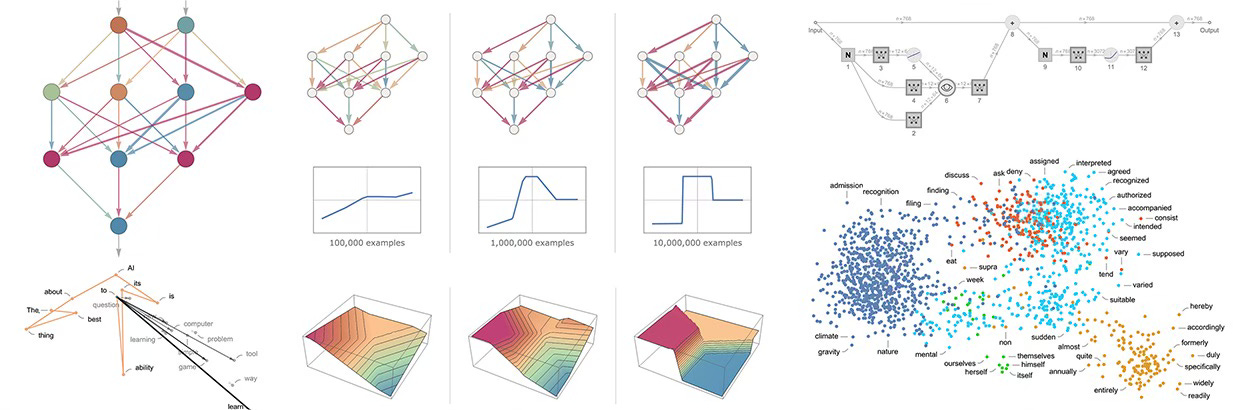
So ‘Explainability’ is likely the relatively more attainable goal, where the AI is asked to at least serve up the top sources used to make up the answers provided. That’s what we’re starting to see from the AI driven prompts and searches being served up by OpenAI with help from Microsoft Bing, Google Bard with help from Google Search, Meta AI with help from Microsoft Bing leveraging Meta’s open source Llama 2, and similar efforts by the many other companies building next gen Foundation LLM AIs.
The reason I’m focusing on these AI rabbit holes is that ChatGPT and its ilk are a unique early technology product in that they’re open-ended and opaque in their results. One of the first applications that got the personal computer going in the early eighties was the spreadsheet from companies like Lotus 123 and others. Those products, and subsequent PC and Internet applications had the above troika of explainability, interpretability, and reliability down cold.
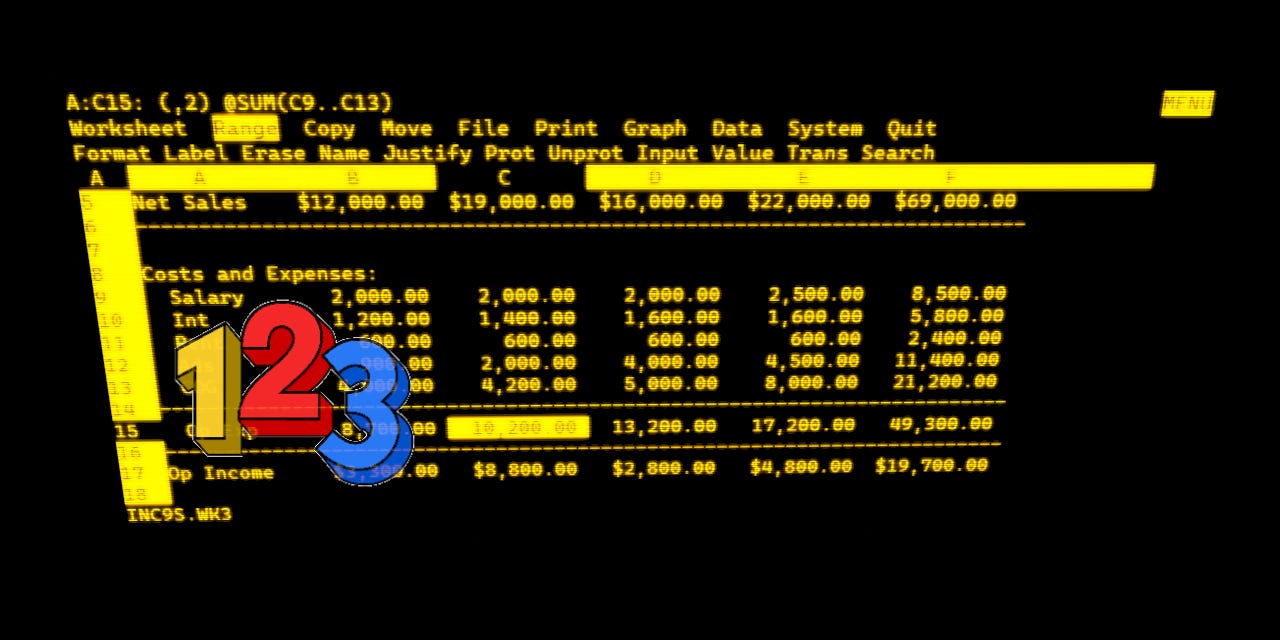
It might take some time, but the results of one or many spreadsheets could be figured out and relied on at the end of the day by mere mortals.
That is not the case with even the early versions of AI technologies like ChatGPT on OpenAI’s GPT-4 LLM AI and other products. As Tech luminary Benedict Evans asks:
“ChatGPT and LLMs can do anything (or look like they can), so what can you do with them? How do you know? Do we move to chat bots as a magical general-purpose interface, or do we unbundle them back into single-purpose software?”
“How is this useful? What do you do with a technology that promises it can do anything?”
“You can ask anything and the system will try to answer, but it might be wrong; and, even if it answers correctly, an answer might not be the right way to solve the problem.”
“ChatGPT is an intern that can write a first draft, or a hundred first drafts, but you’ll have to check it.”
We’re far from a place where we can clearly interpret, explain, and ultimately rely on the results from these AI technologies. There’s a lot to bundle and unbundle here before we figure out the optimal way to use these technologies. Even as we figure out how to bake it into all manner of consumer and business applications, and give it ‘multimodal’ capabilities to ‘listen’ to us, talk to us, and answer us with seeming authority, but generally uncertain reliability. Generally at least one out of five results are incorrect. So human checks are critical.
And this is at the earliest of stages, where the AI is barely getting started to do interesting things. The next generations are supposed to be a thousand times or more powerful in just a few years.
So yes, we have a lot of work to do making sure we can explain, interpret and rely on these technologies ahead. While we’re building them and deploying them as fast as we can. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)