


AI: Impacting Nvidia's World. RTZ #385
...1-bit LLMs (1.58 Bits) that change 'AI Matrix Math'

The world loves stories of epic battles, meteoric rises but also relishes the world of immense falls. So it’s no wonder that Axios today is reminding us that Nvidia’s fate in this AI Tech Wave may echo that of Cisco in the Internet Tech Wave of the nineties. They pithily summarize it as follows:
“Something like that happened 25 years ago. Cisco, which sold the routers every company needed to get online, was the Nvidia of the '90s internet boom. Its stock price chart in the late '90s looks very similar to Nvidia's today.”

“From 1998 to 2000, Cisco quintupled in price — and then, from 2000 to 2002, it collapsed, when a hardware glut arrived just as a market downturn dampened demand.”
“The bottom line: The "sell pickaxes to miners" phase of every tech gold rush is real — but it never lasts that long.”
As someone who looks at tech waves on a secular basis from the ground up, and from someone who was at the Internet table in the nineties as a professional analyst, I’d say this comparison is a bit off.
Nvidia is not Cisco in this wave. While Cisco’s routers did help move the networks of the nineties into the internet protocol set of technologies, the role of Nvidia AI GPU chips, ‘accelerated computing’ data center super computing infrastructure is FAR different. It’s a hardware/software ecosystem optimized to do the mind-bending amounts of exponential ‘AI matrix math’ as LLM and Generative AI technologies are scaled up over the next few years. As I’ve long said here, ‘AI’ without Nvidia GPU clusters and CUDA software computations at scale, are just two non-adjacent letters in the alphabet.

And Nvidia’s founder/CEO Jensen Huang is executing on a well thought out plan to build out its products and services ahead of that scaling. Like a railway team building out the next 100 miles of track ahead of a train rolling down the current tracks at full speed.
I’d say the risks to Nvidia, if any, would come from fundamental AI computation innovations that could still be invented, given the very, very early days of this AI Tech Wave. Especially in terms of how the underlying technologies work.
One such possible innovation is this recent AI research paper (Febtusty 27, 2024), titled “The Era of 1-bit LLMs: ALl Large Language (LLM) models are in 1.58 Bits”:
“Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs).”
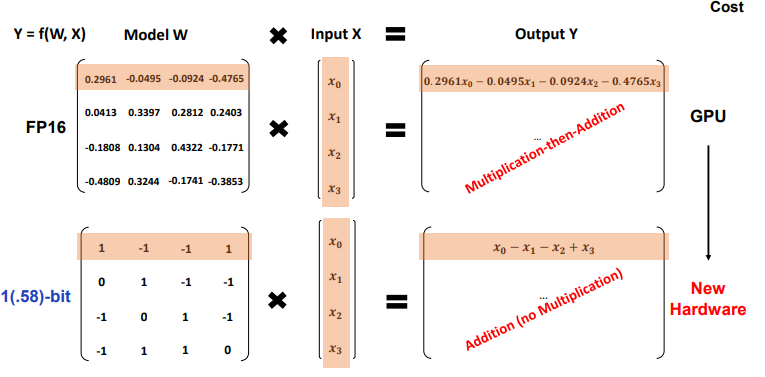
“In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption.”

“More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.”
It’s a fascinating read, and the possibilities for LLM AI are POTENTIALLY profound indeed. Running ever scaling LLM AI models to come with exponentially less computation intensity on AI GPUs, on-board high bandwidth memory (HBM), and far less power demands on that computation. Even as entire countries are looking to invest tens of billions in Nvidia AI hardware and software infrastructure, for ‘Sovereign AI’ data centers.

Menu Gupta explains it bit further here in “What are 1-bit LLMs?”:
“The Generative AI world is racing and the new addition to this fast-evolving space is 1-bit LLMs. You might not believe it, but this can change a lot of things and can help eliminate some of the biggest challenges associated with LLMs, especially their huge size.”
“In a general scenario (not always), the weights of any Machine Learning model, be it LLMs or Logistic Regression, are stored as 32-bit floating points or 16-bit floating point.”
“This is the root cause of why we aren’t able to use models like GPT or other bigger models in local systems and production as these models have a very high number of weights leading to huge sizes due to high precision value for weights.”
He goes onto explain how a current 7 billion parameter (7B) LLM model that needs total memory requirements of 26 gigabytes (GB), could be fit in under a gigabyte.
“This is huge and eventually eliminates several devices that can’t use it including mobile phones as they don’t have this big storage or hardware capacity to run these models.”
“In 1-bit LLMs, only 1 bit (i.e. 0 or 1) is used to store the weight parameters compared to 32/16 bits in traditional LLMs. This reduces the overall size by a big percentage hence enabling even smaller devices to use LLMs.”
“The first-of-its-kind 1-bit LLM, BitNet b1.58 right now uses 1.58 bits per weight (and hence not an exact 1-bit LLM) where a weight can have 3 possible values (-1,0,1).”
The whole piece is worth a read, along with the video link.
But the high-level takeaway is as follows:
“This looks to be quite promising and if the claims are true, we are in for a treat.”
Treat indeed is doable at scale. With AI hardware and software redone to optimize for this ‘1.58 bit’ approach.
AI computations that could be done far easier on local, on-prem and on device semiconductors (like what Apple is attempting to do at scale). And potentially far less need for tens and hundreds of billions in AI data centers, AI infrastructure, and importantly power demands on an already stretched power grid.
Truly ‘Small AI’ done at ‘Big AI’ scale far sooner, and far cheaper than currently envisioned and feasible.
It’d be like someone invented a way to make all delicious foods have a fraction of the impact on humans increasing weight and becoming obese, while keeping the energy provision and importantly taste unaffected.
Almost too good to be true. And may indeed turn out to be the case for AI. The loops in the AI Tech Stack chart below would be have multiple zeroes taken off them in terms of computation costs and power demands. From hundreds of billions to tens and hundreds of millions. And lower.
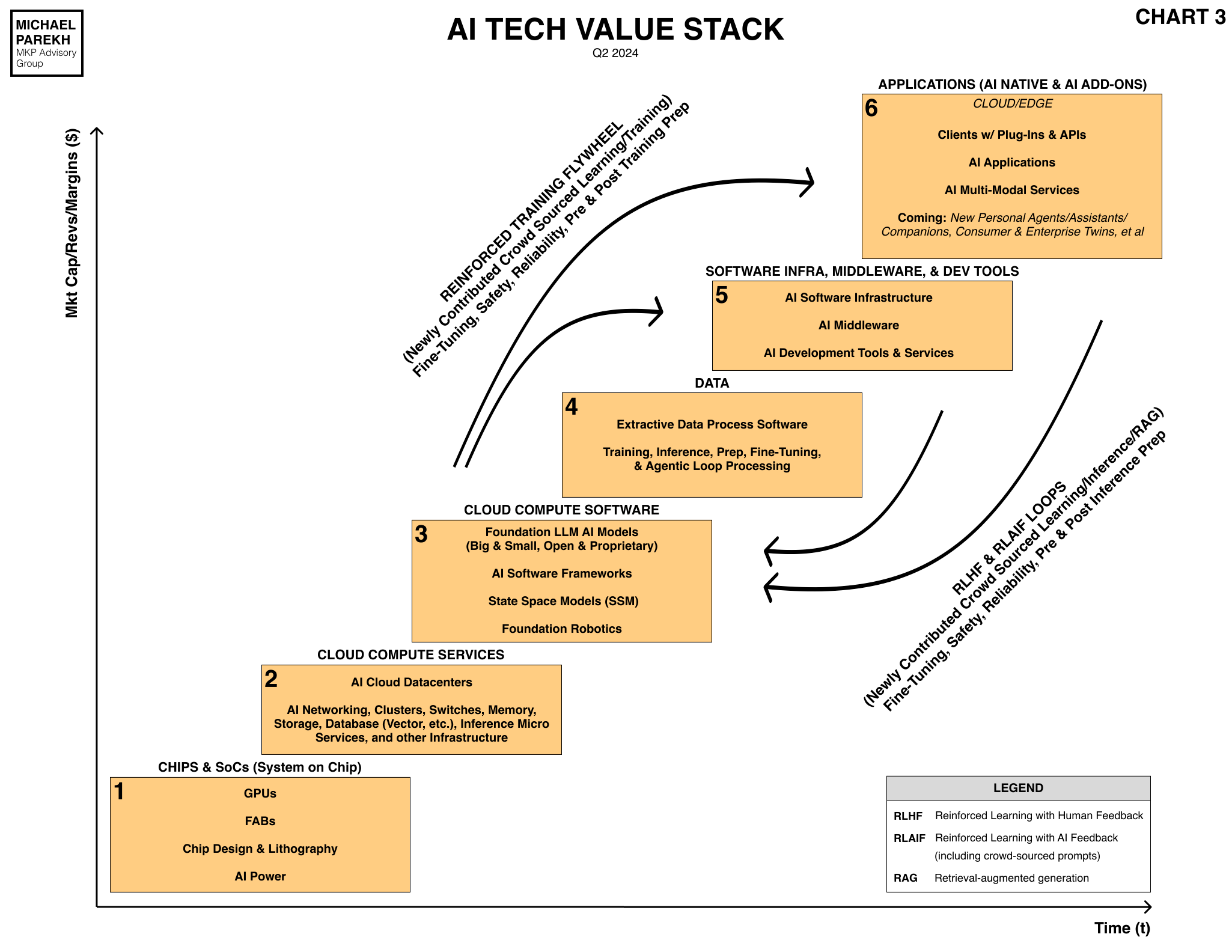
But the global AI community is on this and other tracks to make AI computations far more efficient than today, both for training and inference. And all the reinforcement learning loops/RAGs in between.
But current work on 1-bit LLMs building on BitNet b1.58 are promising. Especially for companies like Apple that is working aggressively to quantize their on device LLMs to smaller footprints, higher computational efficiency, at meaningful lower power draws.
If anything could impact Nvidia’s current AI ‘accelerated computing’ roadmap, it’d be these kinds of changes in the way to do LLM AI matrix math at a fundamental level. We’re a while away from there, but the early research is promising.
So if we’re trying to understand what Nvidia’s fate may be gong forward, the twists and turns are going to come from these and other types of AI research and innovations above. Not from a high-level comparison to Cisco in the nineties.
These and other more efficient LLM matrix math innovations also invoke Jevon’s Law. That rather than REDUCING the demand for AI compute both in the cloud and devices, it counter-intuitively INCREASES it. This has happened with technology for many generations of tech waves.
As for Nvidia, they are more than likely to figure out how to take innovations like these in strides and work it to their long-term advantage.
Just like Facebook/Meta transitioned from web-based social media to a mobile-based world of social media, after their IPO. Not to mention Apple’s changes a few years later, in the ad ecosystem that impacted Meta’s business model for a few quarters.
Nvidia is a founder/CEO led big tech as well.
Too early to count them out, through changes, twists and turns in AI technologies.
Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)