
AI: 'Be Prepared', for AI Scouts too
...OpenAI and Anthropic lead the way on 'Preparedness'


It echoes the 1907 beginning of the Scout’s motto: ‘Be Prepared’.
It’s fitting we end the first full year after OpenAI’s ‘ChatGPT moment’, AND the civil war at the company over ‘Speed vs Safety’, with OpenAI announcing its ‘Preparedness’ around AI ‘SuperAlignment’ for Foundation, Frontier LLM (large language model) AIs. That of course being the major Superalignment initiative announced back in early July by OpenAI Chief Scientist Ilya Sutskever (Yes, THAT Ilya).
Back then, OpenAI committed up to 20% of the company’s ‘compute power’ to AI Safety focused on ‘SuperAlignment’ with human existence. As they declared back then:
“Superintelligence will be the most impactful technology humanity has ever invented, and could help us solve many of the world’s most important problems. But the vast power of superintelligence could also be very dangerous, and could lead to the disempowerment of humanity or even human extinction.”
“While superintelligence seems far off now, we believe it could arrive this decade.”
“Managing these risks will require, among other things, new institutions for governance and solving the problem of superintelligence alignment”.

Fast forward to now, OpenAI announced the following on its new ‘Preparedness’ initiative:
“The study of frontier AI risks has fallen far short of what is possible and where we need to be. To address this gap and systematize our safety thinking, we are adopting the initial version of our Preparedness Framework. It describes OpenAI’s processes to track, evaluate, forecast, and protect against catastrophic risks posed by increasingly powerful models.”
Specifically, the company underlined:
“The Preparedness team is dedicated to making frontier AI models safe.”
“We have several safety and policy teams working together to mitigate risks from AI. Our Safety Systems team focuses on mitigating misuse of current models and products like ChatGPT. Superalignment builds foundations for the safety of superintelligent models that we (hope) to have in a more distant future. The Preparedness team maps out the emerging risks of frontier models, and it connects to Safety Systems, Superalignment and our other safety and policy teams across OpenAI.”
“OpenAI is setting another framework to evaluate whether the humans and models are prepared to face each other.”
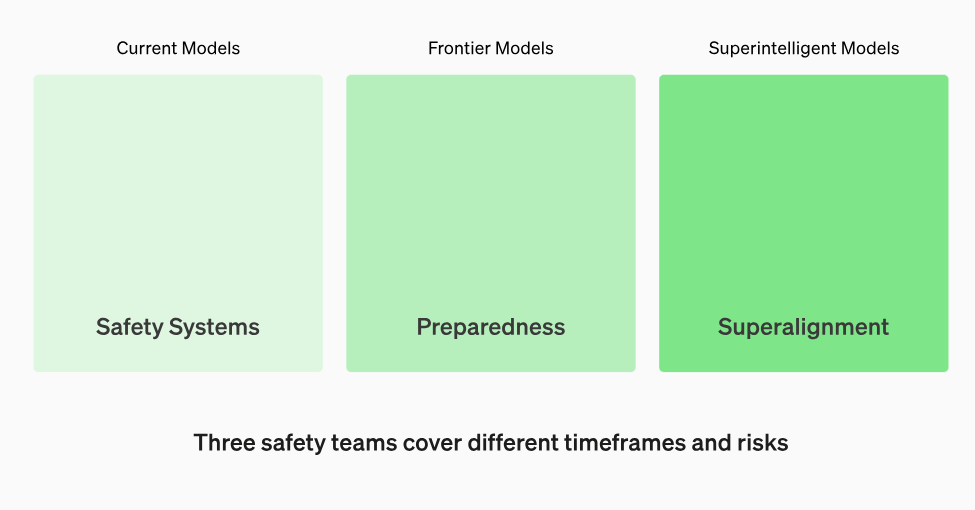
“Open AI has many safety teams within it. The Superalignment team focuses on existential risks, and talks about artificial superintelligence that will surpass humans. At the same time, it has model safety teams that make sure models like GPT-3.5 and GPT-4 are safe for everyday use.”
“This new preparedness team will focus on the soon-to-come risks of the most advanced AI models AKA frontier models. Its work will be grounded in fact with a builder mindset.”
All this of course builds on the ‘Catastrophic AI Risk’ initiatives announced recently by both OpenAI and arch-competitor Anthropic, the other Foundation LLM AI company. Yes, that Anthropic founded with ex-OpenAI co-founders, who recently added both Amazon and Google as multi-billion dollar investment partners. As the Information noted a few days ago:
“OpenAI’s technology and revenue is ahead of Anthropic’s, but when it comes to practices aimed at making sure people don’t use generative artificial intelligence to harm society, OpenAI seems to be playing catch-up. In a 26-page document published Monday, OpenAI discussed how it evaluates AI models for “catastrophic risks” before selling them to the public.”
The move comes three months after Anthropic published its own, 22-page document on how it’s getting ahead of its AI’s dangers.”
All this of course is presumably what regulators in Washington and elsewhere want to see, as they figure out what they should and shouldn’t do to curb possible risks of current and future Foundation LLM AI models, and how fast it should all happen.
As I’ve said before, these types of moves are unprecedented this early in major technology waves, but such is the unique nature of the AI Tech Wave as we end 2023 with big investment chips on the table.

I’ll reiterate what I said recently in “Nothing to Fear but Fear itself”:
“We need to be mindful of this academic navel-gazing fear, and balance it with the affirmative potential of AI technologies in particular. Especially if that Fear is transmitted to mainstream users and regulators BEFORE the technologies are even baked and anywhere close to their eventual potential. Yes, EVEN with the exponential curves of AI ahead of us. Even while we barely understands how and why it works.”

So we're definitely fine to ‘Be Prepared’, whatever may come ahead. But let’s not be prematurely fearful of fear itself. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)