
AI: Evaluating AIs. RTZ #351
...an exponentially difficult task ahead


As the world is flooded with new LLM and SLM (Small Language Model) AIs every day, it’s useful to remind ourselves of immensity of the task to compare and evaluate these models with one another. And why it’s so easy to get turned around. As this Techcrunch piece explains in “Why it’s impossible to review AIs”:
“Every week seems to bring with it a new AI model, and the technology has unfortunately outpaced anyone’s ability to evaluate it comprehensively. Here’s why it’s pretty much impossible to review something like ChatGPT or Gemini.”

“The tl;dr: These systems are too general and are updated too frequently for evaluation frameworks to stay relevant, and synthetic benchmarks provide only an abstract view of certain well-defined capabilities. Companies like Google and OpenAI are counting on this because it means consumers have no source of truth other than those companies’ own claims. So even though our own reviews will necessarily be limited and inconsistent, a qualitative analysis of these systems has intrinsic value simply as a real-world counterweight to industry hype.”
“Let’s first look at why it’s impossible, or you can jump to any point of our methodology here:”
The whole piece is worth reading to understand the exponential difficulty of evaluating and comparing these models large and small. Not the least of it of course being that unlike traditional computer software, generative/LLM AI is based on probabilistic computing.
The answer varies to the same questions almost every time, due to the constant changes to the models with every inference reinforcement learning loop, within and across models.
That makes the Evaluation process of these models (aka ‘evals’), so murky. As the piece goes on to explain:
“They can do many things, but a huge proportion of them are parlor tricks or edge cases, while only a handful are the type of thing that millions of people will almost certainly do regularly. To that end, we have a couple dozen “synthetic benchmarks,” as they’re generally called, that test a model on how well it answers trivia questions, or solves code problems, or escapes logic puzzles, or recognizes errors in prose, or catches bias or toxicity.”
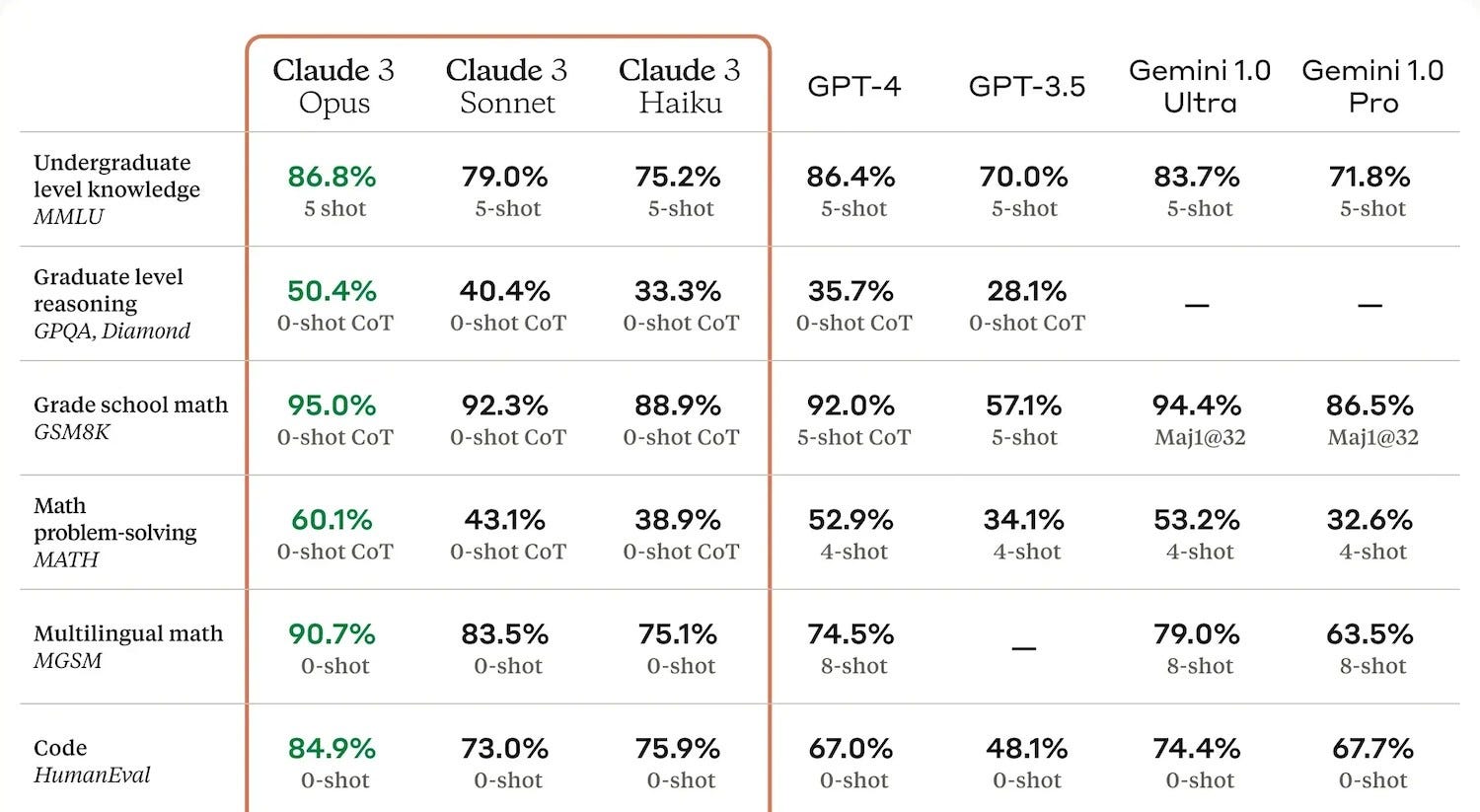
And the results can be constantly ‘gamed’:
“These generally produce a report of their own, usually a number or short string of numbers, saying how they did compared with their peers. It’s useful to have these, but their utility is limited. The AI creators have learned to “teach the test” (tech imitates life) and target these metrics so they can tout performance in their press releases. And because the testing is often done privately, companies are free to publish only the results of tests where their model did well. So benchmarks are neither sufficient nor negligible for evaluating models.”

These problems of measuring, evaluating and explaining big and small AI models , this early in the AI Tech Wave, is going to get worse, not better, for the near term. As the models proliferate and exponentially get better, leveraging the AI Scaling Laws I’ve discussed before, the task ahead is almost a futile task.
But the reasons why are important to understand. And hope this brief description of the ‘Explainability’ evaluation task provides a glimpse into the issues involved. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)