


AI: “Show me the Money”
...'Extractive Data' war intensifies


As Large Language Model AI gets even more voracious for Data to train on, the tug of war is intensifying for compensation to the creators of all the stuff being scraped off the internet. The industry calls it ‘Extractive Data’, appropriately enough, as I’ve outlined and illustrated before:

This is an issue I’ve been writing about these accelerating tussles for a while now, and it is all increasingly coming to a head this year. This data is at the heart of the initial Foundation LLM AI model ‘Training’ data, and the subsequent critical “Reinforcement Learning ‘Inference’ loops” that make these models do their ‘emergent’ magic, and become far more capable over time. As the WSJ reports on the latest ‘Outcry’:
“A collective cry is breaking out as authors, artists and internet publishers realize that the generative AI phenomenon sweeping the globe is built partly on the back of their work.”
“The emerging awareness has set up a war between the forces behind the inputs and the outputs of these new artificial-intelligence tools, over whether and how content originators should be compensated. The disputes threaten to throw sand into the gears of the AI boom just as it seems poised to revolutionize the global economy.”
Goldman Sachs is estimating $7 trillion plus in additional GDP growth over the next decade, as I’ve outlined before. The Firm (my former professional alma mater) is also emphasizing the underlying growth of the online content ‘Creator’ Economy growing from $250 billion this year to almost $500 billion by 2027.
The companies behind the Foundation LLM AI models know there are a combination of negotiations and lawsuits ahead, and are getting ready:
“Artificial-intelligence companies including OpenAI, its backer Microsoft, and Google built generative-AI systems such as ChatGPT by scraping oceans of information from the internet and feeding it into training algorithms that teach the systems to imitate human speech. The companies generally say their data use without compensation is permitted, but they have left the door open to discussing the issue with content creators.”
“OpenAI hasn’t revealed much about the data used to train its latest language model, GPT-4, citing competitive concerns. Its prior research papers show that earlier versions of its GPT model were trained in part on English-language Wikipedia pages and data scooped by a nonprofit called Common Crawl. It also trained its software using an OpenAI-compiled corpus of certain Reddit posts that received a user score, or “karma,” of at least three.”
The originators of the underlying content for these and other sites are also ramping up:
“Earlier in July, thousands of authors including Margaret Atwood and James Patterson signed an open letter demanding that top AI companies obtain permission and pay writers for the use of their works to train generative-AI models. Comedian Sarah Silverman and other authors also filed lawsuits against OpenAI and Facebook-parent Meta Platforms for allegedly training their AI models on illegal copies of their books that were captured and left on the internet.”
“News publishers have called the unlicensed use of their content a copyright violation. Some—including Wall Street Journal parent News Corp, Dotdash Meredith owner IAC and publishers of the New Yorker, Rolling Stone and Politico—have discussed with tech companies exploring ways they might be paid for the use of their content in AI training, according to people familiar with the matter.”
As are the biggest online sites that have long been the source material for the LLM AI models for years already:
“Reddit, the social-discussion and news-aggregation site, has begun charging for some access to its content. Elon Musk has blamed AI companies scraping “vast amounts of data” for a recent decision by X, then called Twitter, to limit the number of tweets some users could view. And striking actors and writers have cited concerns that Hollywood studios could use AI to copy their likenesses or eliminate their jobs.”
Some deals are already being cut:
“The Associated Press and OpenAI announced a deal this month for the tech company to license stories in the AP archive.”
And a lot more will come behind these presumably. At the same time, the LLM AI Data scrapers are setting up their base positions and clarifying their starting positions:
“OpenAI and Google have both said they train their AI models on “publicly available” information, a phrase that experts say encompasses a spectrum of content, including from paywalled and pirated sites. OpenAI also said in a statement that it respects the rights of creators and authors, and that many creative professionals use ChatGPT.“
“Tech companies have pointed to the legal doctrine of fair use, which permits the use of copyright material without permission under some circumstances, including if the end product is sufficiently different from the original work. AI proponents say free access to information is vital for technology that learns similarly to people and that has huge potential upsides for how we work and live.”
But the other side is setting up their base positions as well:
“Other proposed class-action lawsuits were filed separately against OpenAI, Microsoft and Google on behalf of internet users alleging that the companies’ scraping of websites to train their AI models violated the users’ privacy rights and copyrights.”
As I said a few weeks ago in a post titled ‘AI: Data and Copyrights’, the next area of contention is likely going to be the vast array of video content in services like Google YouTube, Meta, and TikTok. And then some:
“Soon Google’s YouTube videos, and other video sources could be a new source of Data for Foundation LLM AI models to train on and provide exponentially better AI results to users worldwide.”
“And how the Data all the models are using right now are but ‘a tip of the tip of the iceberg’.”
“But there’s one obvious issue that companies large and small are going to have to navigate before it’s clear sailing in AI land. And that of course, is the issue of IP and copyrights.”
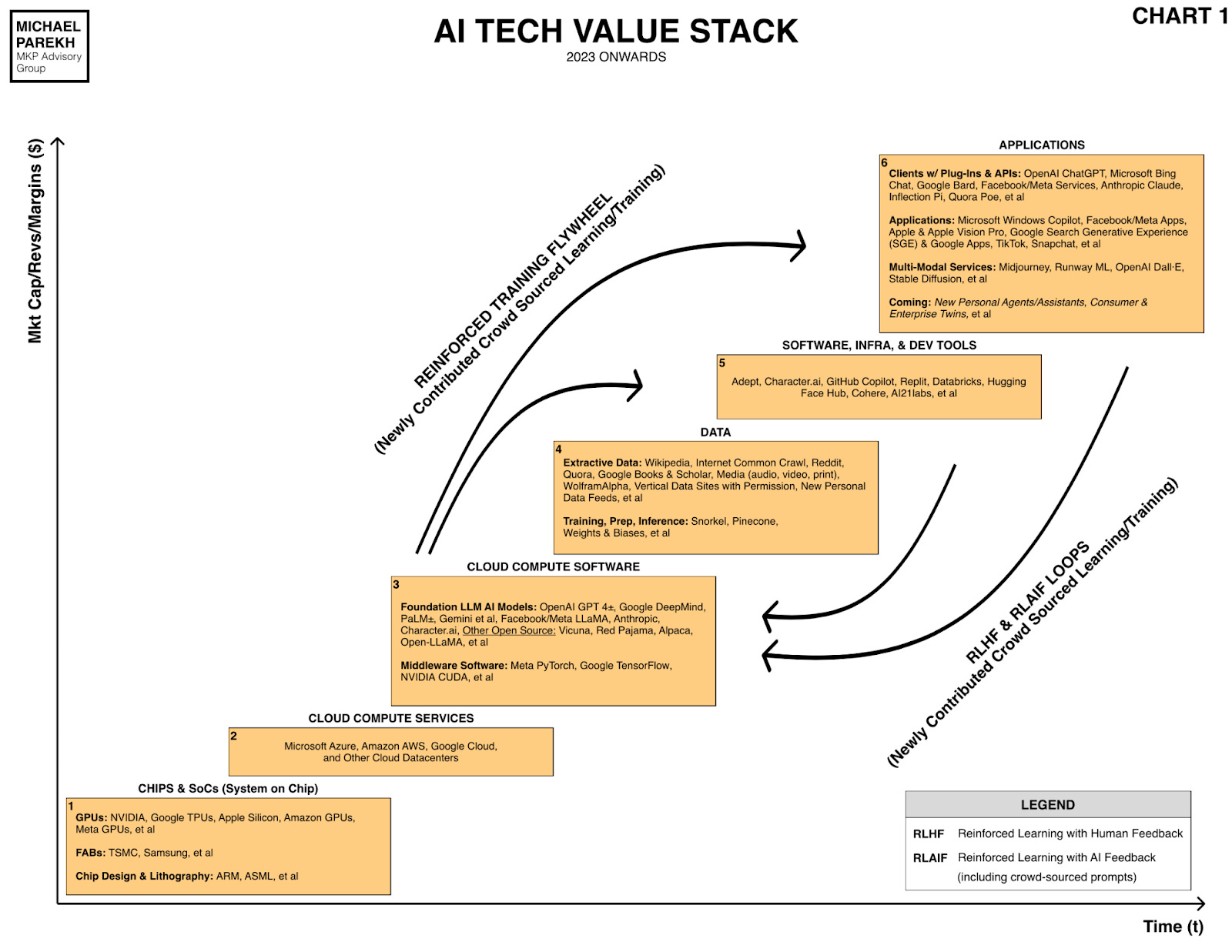
“Since all the Data items in Box 4 in the AI Tech Stack chart are the raw source material to train hundreds and soon thousands of LLM AI models worldwide, and much of that data is material that has IP and copyrights under a different digital world, the question of “Fair Use” and potential copyrights of course comes up. Get ready for some epic tussles.”
The good news this time is that all the stakeholders have seen these Tech models evolve with the PC and the Internet waves before, and know that a lot of this can be negotiated and not just litigated. There is serious money here over time, likely enough for most of the parties.
But there are also a lot of uncertain technology development, and outcomes to be clarified ahead. Certainly a while before all the stakeholders are going to have a clearer view of what’s ahead in terms of the Money flows to be ultimately seen and shown over the next few years. Stay tuned.
As the AI landscape evolves, I predict more negotiations and lawsuits to come. The emerging awareness about content originators' compensation will shape the AI boom's trajectory, making it crucial to find a fair balance. Keep up the fantastic reporting.