


AI: Google AI Research builds on 'Transformers' to 'Titans'. RTZ #606
...this time rethinking AI memory may be the key answer


I started this AI newsletter over 605 daily posts ago on 5/12/23 with “AI: Memory of a Goldfish”. A key point from then:
”MEMORY is the next big Feature race in Foundation LLM AIs, open or closed, large or small”.

Memory in AI has gotten more attention from OpenAI, Google and Anthropic et al, as I noted early last year in ‘Memory not included’.

And I’ve discussed how ‘High Bandwidth Memory’ (HBM) from key companies like SK Hynix of South Korea, are critical inputs in AI infrastructure, that are likely to be in short supply for a few years, especially as Nvidia scales out its AI GPUs and data center infrastructure.
Well, after Google kicking off the whole LLM/Generative AI gold rush with its seminal 2017 AI ‘Attention is all you need’ paper that introduced ‘Transformers’ to generate ‘Intelligence tokens’, and kicked off the ‘Intelligence Age’ penned by OpenAI’s Sam Altman.
Google may now be kicking off a whole new stage in AI research and commercialization with its new ‘Titans’ AI paper, titled “Titans: Learning to Memorize at Test Time”. And this time, the focus is on MEMORY.
Venturebeat explains in “Google’s new neural-net LLM architecture separates memory components to control exploding costs of capacity and compute”:
“A new neural-network architecture developed by researchers at Google might solve one of the great challenges for large language models (LLMs): extending their memory at inference time without exploding the costs of memory and compute. Called Titans, the architecture enables models to find and store during inference small bits of information that are important in long sequences.”
“Titans combines traditional LLM attention blocks with “neural memory” layers that enable models to handle both short- and long-term memory tasks efficiently. According to the researchers, LLMs that use neural long-term memory can scale to millions of tokens and outperform both classic LLMs and alternatives such as Mamba while having many fewer parameters.”

They explain how Transformers for LLMs then ties to Titans in Memory today, with Google Gemini and others:
“The classic transformer architecture used in LLMs employs the self-attention mechanism to compute the relations between tokens. This is an effective technique that can learn complex and granular patterns in token sequences. However, as the sequence length grows, the computing and memory costs of calculating and storing attention increase quadratically.”
The problem is that memory does not scale well as LLM AIs Scale in capabilities:
“More recent proposals involve alternative architectures that have linear complexity and can scale without exploding memory and computation costs. However, the Google researchers argue that linear models do not show competitive performance compared to classic transformers, as they compress their contextual data and tend to miss important details.”

Which requires a rethink on how memory interacts with LLMs at the chip infrastructure level, and the overall software architecture:
“The ideal architecture, they suggest, should have different memory components that can be coordinated to use existing knowledge, memorize new facts, and learn abstractions from their context.”
And they took inspiration from how human memory works:
“We argue that in an effective learning paradigm, similar to [the] human brain, there are distinct yet interconnected modules, each of which is responsible for a component crucial to the learning process,” the researchers write.
“Memory is a confederation of systems — e.g., short-term, working, and long-term memory — each serving a different function with different neural structures, and each capable of operating independently,” the researchers write.
“To fill the gap in current language models, the researchers propose a “neural long-term memory” module that can learn new information at inference time without the inefficiencies of the full attention mechanism. Instead of storing information during training, the neural memory module learns a function that can memorize new facts during inference and dynamically adapt the memorization process based on the data it encounters. This solves the generalization problem that other neural network architectures suffer from.”
And the BIG breakthrough here seems to be how to bake in ‘Surprise’ elements into computer memory, the way our brains seem to do it:
“To decide which bits of information are worth storing, the neural memory module uses the concept of “surprise.” The more a sequence of tokens differs from the kind of information stored in the model’s weights and existing memory, the more surprising it is and thus worth memorizing. This enables the module to make efficient use of its limited memory and only store pieces of data that add useful information to what the model already knows.”
“To handle very long sequences of data, the neural memory module has an adaptive forgetting mechanism that allows it to remove information that is no longer needed, which helps manage the memory’s limited capacity.”
“The memory module can be complementary to the attention mechanism of current transformer models, which the researchers describe as “short-term memory modules, attending to the current context window size. On the other hand, our neural memory with the ability to continuously learn from data and store it in its weights can play the role of a long-term memory.”
All of this then leads to the layout below:
Titan architecture

“The researchers describe Titans as a family of models that incorporate existing transformer blocks with neural memory modules. The model has three key components: the “core” module, which acts as the short-term memory and uses the classic attention mechanism to attend to the current segment of the input tokens that the model is processing; a “long-term memory” module, which uses the neural memory architecture to store information beyond the current context; and a “persistent memory” module, the learnable parameters that remain fixed after training and store time-independent knowledge.”
The above then drives the incredibly complex layers of statistical computations between the attention and memory layers:
“The researchers propose different ways to connect the three components. But in general, the main advantage of this architecture is enabling the attention and memory modules to complement each other. For example, the attention layers can use the historical and current context to determine which parts of the current context window should be stored in the long-term memory. Meanwhile, long-term memory provides historical knowledge that is not present in the current attention context.”
So how does all this measure up in practice?
“The researchers ran small-scale tests on Titan models, ranging from 170 million to 760 million parameters, on a diverse range of tasks, including language modeling and long-sequence language tasks. They compared the performance of Titans against various transformer-based models, linear models such as Mamba and hybrid models such as Samba.”

The BOTTOM LINE on all this is fairly good news:
“Titans demonstrated a strong performance in language modeling compared to other models and outperformed both transformers and linear models with similar sizes.”
“The performance difference is especially pronounced in tasks on long sequences, such as “needle in a haystack,” where the model must retrieve bits of information from a very long sequence, and BABILong, where the model must reason across facts distributed in very long documents. In fact, in these tasks, Titan outperformed models with orders of magnitude more parameters, including GPT-4 and GPT-4o-mini, and a Llama-3 model enhanced with retrieval-augmented generation (RAG).”

“Moreover, the researchers were able to extend the context window of Titans up to 2 million tokens while maintaining the memory costs at a modest level.”
All this means, that this research could kick off a whole new landscape of AI opportunities, with clear next steps:
“The models still need to be tested at larger sizes, but the results from the paper show that the researchers have still not hit the ceiling of Titans’ potential.”
“With Google being at the forefront of long-context models, we can expect this technique to find its way into private and open models such as Gemini and Gemma.”
And lead to much more reliable and scalable AIs, with far lower operating cost efficiencies over time:
“With LLMs supporting longer context windows, there is growing potential for creating applications where you squeeze new knowledge into your prompt instead of using techniques such as RAG. The development cycle for developing and iterating over prompt-based applications is much faster than complex RAG pipelines. Meanwhile, architectures such as Titans can help reduce inference costs for very long sequences, making it possible for companies to deploy LLM applications for more use cases.”
And Google again is very much in the AI leadership role along with its peers:
“Google plans to release the PyTorch and JAX code for training and evaluating Titans models.”
I recently discussed the importance of inference based ‘Test Time Compute’ (TTC) in my recent discussion of the updated AI Tech Stack (see Legends box below):
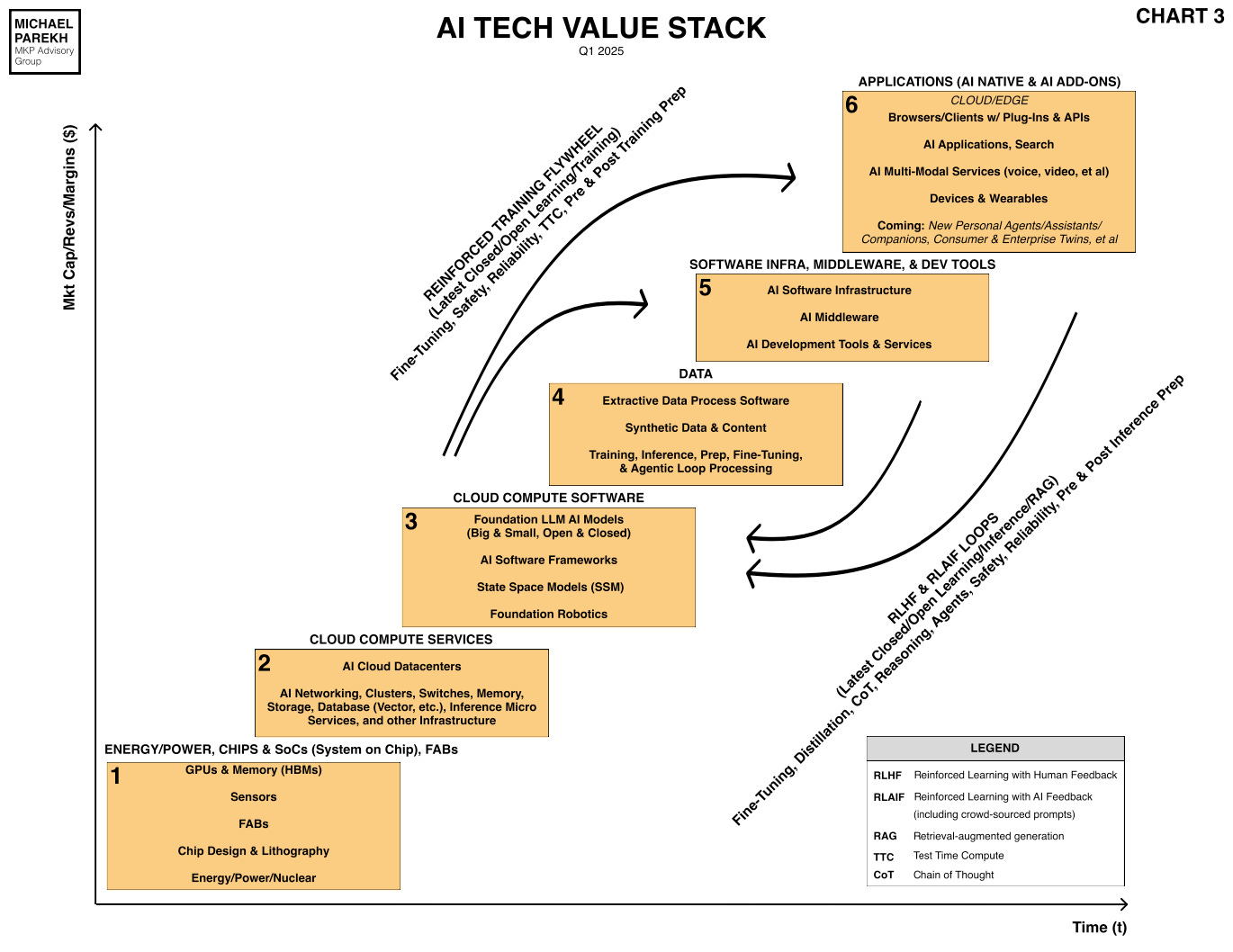
And this new area of memory search has potential implications for the industry’s roadmap to AGI, via AI Reasoning and Agents.

All of it again underlining that this AI Tech Wave is very different from prior tech waves, in that its core technologies have barely gotten started to being developed. Memory now included. Stay tuned.
(NOTE: The discussions here are for information purposes only, and not meant as investment advice at any time. Thanks for joining us here)